Research Projects
DeSKO: Stability-Assured Robust Control with a Deep Stochastic Koopman Operator
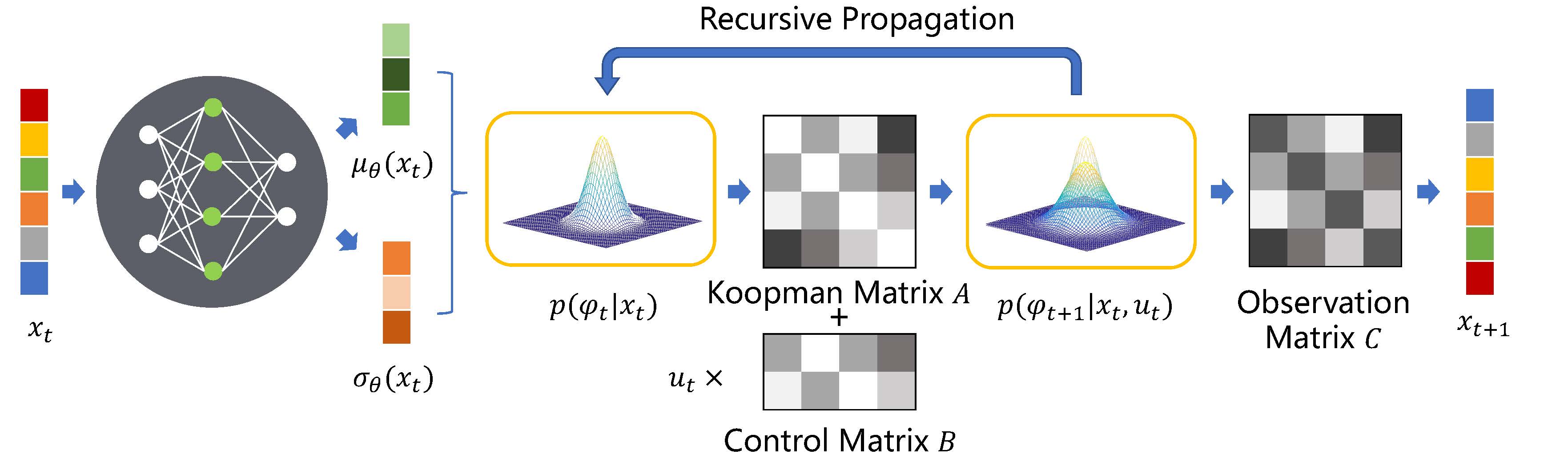 |
Abstract: The Koopman operator theory linearly describes nonlinear dynamical systems in a high-dimensional functional space and it allows to apply linear control methods to highly nonlinear systems. However, the Koopman operator does not account for any uncertainty in dynamical systems, causing it to perform poorly in real-world applications.
Therefore, we propose a deep stochastic Koopman operator (DeSKO) model in a robust learning control framework to guarantee stability of nonliner stochastic systems. The DeSKO model can capture a dynamical system's uncertainty and infer a distribution of observables. We use the inferred distribution to design a robust, stabilizing closed-loop controller for a dynamical system. Modeling and control experiments on several advanced control benchmarks show that our framework is more robust and scalable than state-of-the-art deep Koopman operators and reinforcement learning methods. Tested benchmarks include a soft robotic arm, a legged robot, and a biological gene regulatory network. We also demonstrate that this robust control method resists previously unseen uncertainties, such as external disturbances, with a magnitude of up to five times the maximum control input. Our approach opens up new possibilities in learning control for high-dimensional nonlinear systems while robustly managing internal or external uncertainty. |
Actor-Critic Reinforcement Learning for Control with Stability Guarantee
 |
Abstract: Reinforcement Learning (RL) and its integration with deep learning have achieved impressive performance in various robotic control tasks, ranging from motion planning and navigation to end-to-end visual manipulation. However, stability is not guaranteed in model-free RL by solely using data. From a control-theoretic perspective, stability is the most important property for any control system, since it is closely related to safety, robustness and reliability of robotic systems. In this paper, we propose an actor-critic RL framework for control which can guarantee the closed-loop stability by employing the classic Lyapunov's method in control theory. First of all, a data-based stability theorem is proposed for stochastic nonlinear systems modeled by Markov decision process. Then we show that the stability condition could be exploited as the critic in the actor-critic RL to learn a controller/policy. At last, the effectiveness of our approach is evaluated on several well-known 3-dimensional robot control tasks and a synthetic biology gene network tracking task in three different popular physics simulation platforms. As an empirical evaluation on the advantage of stability, we show that the learned policies can enable the systems to recover to the equilibrium or way-points when interfered by uncertainties such as system parametric variations and external disturbances to a certain extent. |
Reinforcement Learning Control with Probabilistic Stability Guarantee
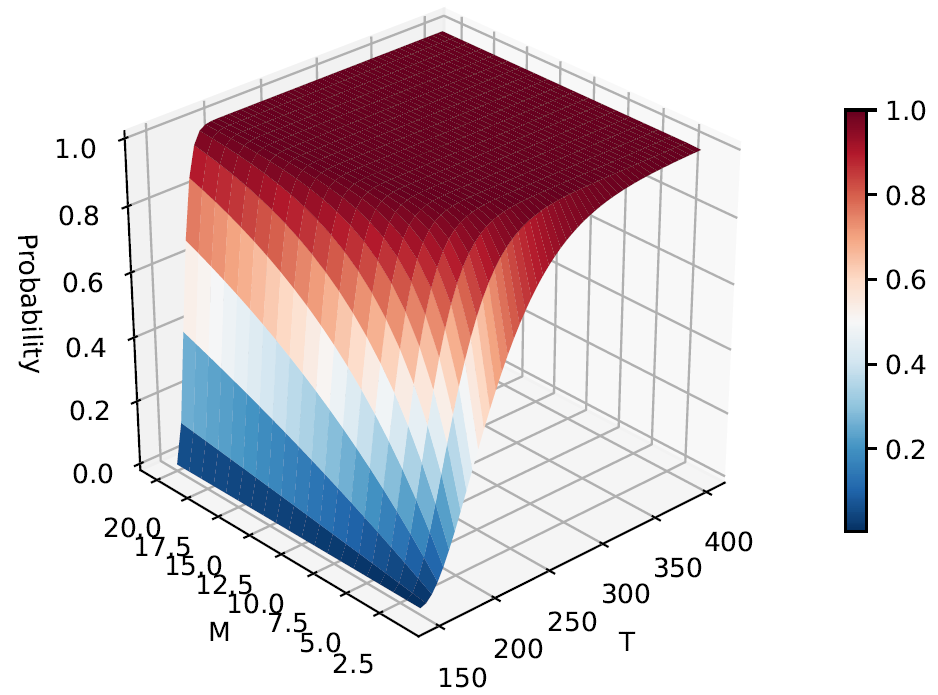 |
Abstract:Reinforcement learning is promising to control complex stochastic nonlinear dynamical systems modeled by Markov Decision Process (MDP) for which the traditional control methods are hardly applicable. However, in control theory, the stability of a closed-loop system can be hardly guaranteed using the policy/controller learned solely from samples which presents a major bottleneck for its application in control engineering. In this paper, we will combine Lyapunov's method in control theory and stochastic analysis to analyze the mean square stability of MDP in a model-free manner. For the first time, the probabilistic finite sample-based stability theorems under which the system is guaranteed to be stable with a certain probability are given. And the probability is a monotone increasing function of the number of samples, i.e., the probability is 1 when the samples are infinite. Based on the novel stability theorems, an algorithm using policy gradient is proposed to learn the controller and the Lyapunov function simultaneously. A connection with the classic REINFORCE algorithm is also revealed as an independent interest. |
Reinforcement Learning Control of Constrained Dynamic Systems with Uniformly Ultimate Boundedness Stability Guarantee
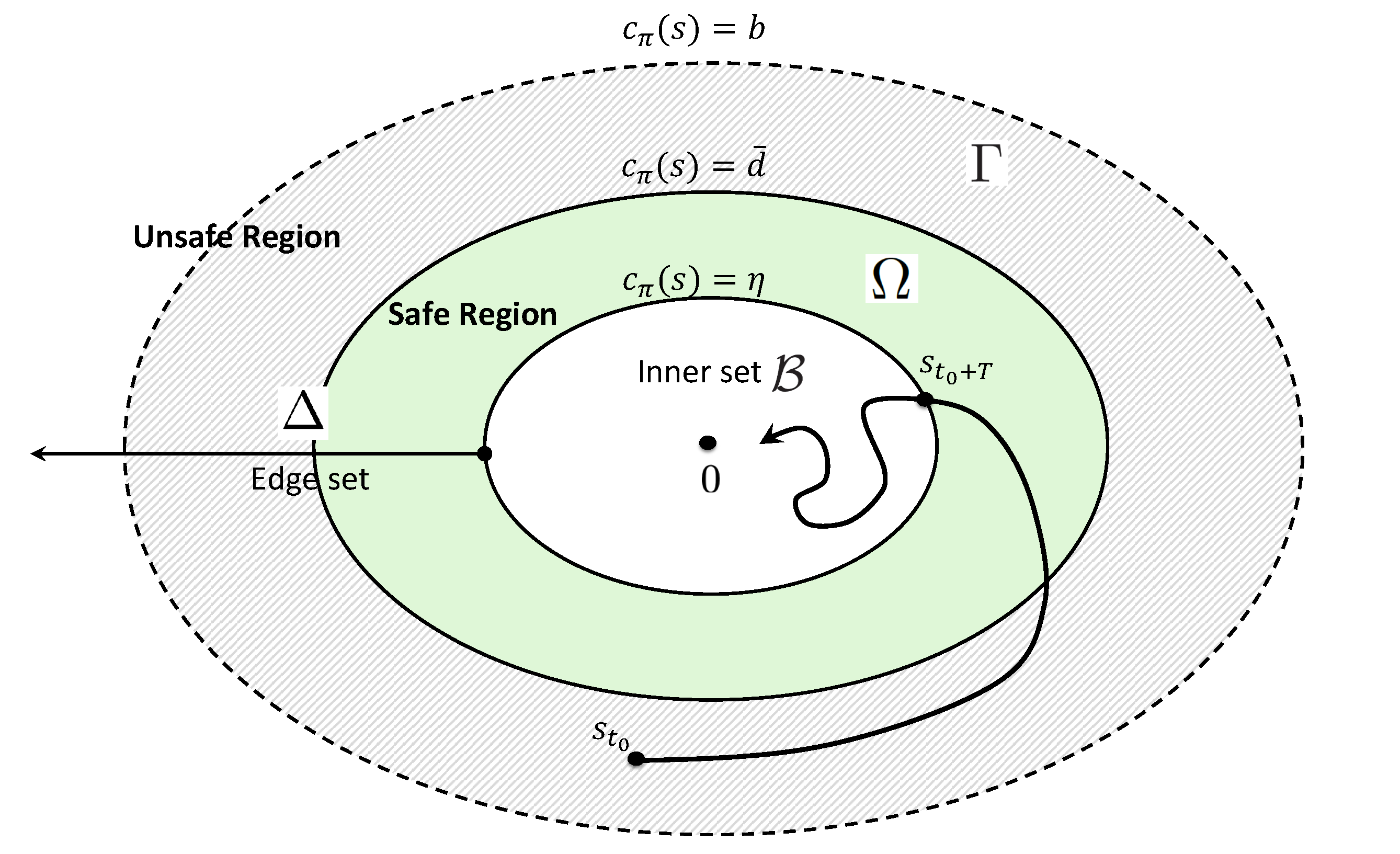 |
Abstract: Reinforcement learning (RL) is promising for complicated stochastic nonlinear control problems. Without using a mathematical model, an optimal controller can be learned from data evaluated by certain performance criteria through trial-and-error. However, the data-based learning approach is notorious for not guaranteeing stability, which is the most fundamental property for any control system. In this paper, the classic Lyapunov's method is explored to analyze the uniformly ultimate boundedness stability (UUB) solely based on data without using a mathematical model. It is further shown how RL with UUB guarantee can be applied to control dynamic systems with safety constraints. Based on the theoretical results, both off-policy and on-policy learning algorithms are proposed respectively. As a result, optimal controllers can be learned to guarantee UUB of the closed-loop system both at convergence and during learning. The proposed algorithms are evaluated on a series of robotic continuous control tasks with safety constraints. In comparison with the existing RL algorithms, the proposed method can achieve superior performance in terms of maintaining safety. As a qualitative evaluation of stability, our method shows impressive resilience even in the presence of external disturbances. |
H∞ Model-free Reinforcement Learningwith Robust Stability Guarantee
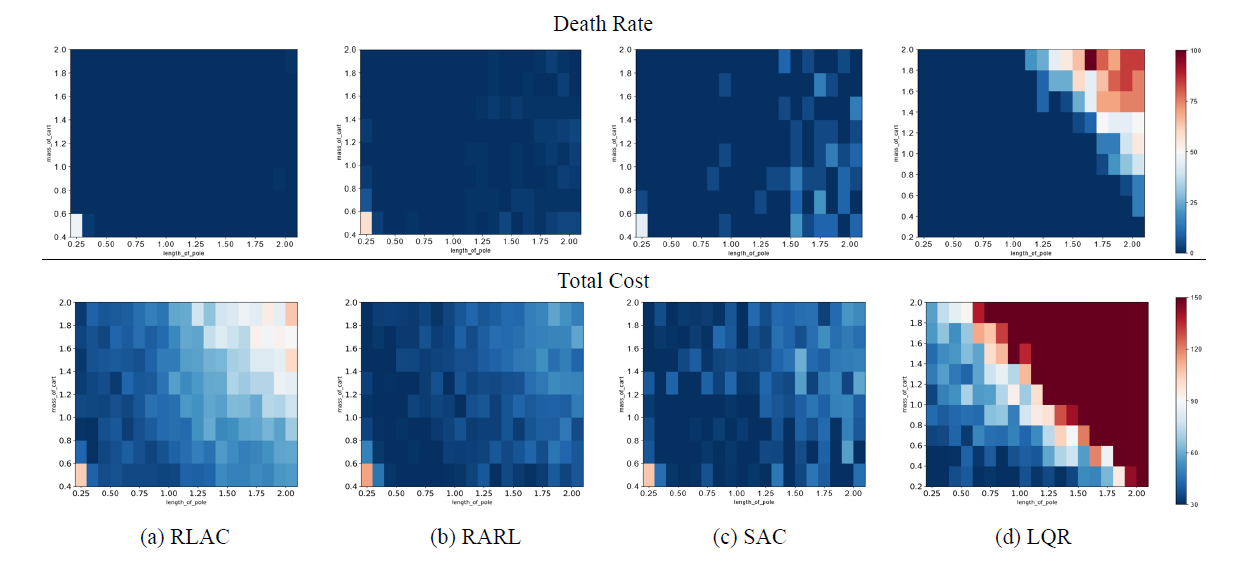 |
Abstract: Reinforcement learning is showing great potentials in robotics applications, including autonomous driving, robot manipulation and locomotion. However, with complex uncertainties in the real-world environment, it is difficult to guarantee the successful generalization and sim-to-real transfer of learned policies theoretically. In this paper, we introduce and extend the idea of robust stability and H∞ control to design policies with both stability and robustness guarantee. Specifically, a sample-based approach for analyzing the Lyapunov stability and performance robustness of a learning-based control system is proposed. Based on the theoretical results, a maximum entropy algorithm is developed for searching Lyapunov function and designing a policy with provable robust stability guarantee. Without any specific domain knowledge, our method can find a policy that is robust to various uncertainties and generalizes well to different test environments. In our experiments, we show that our method achieves better robustness to both large impulsive disturbances and parametric variations in the environment than the state-of-art results in both robust and generic RL, as well as classic control. |
Asynchronous Observer Design for Switched Linear Systems: A Tube-Based Approach
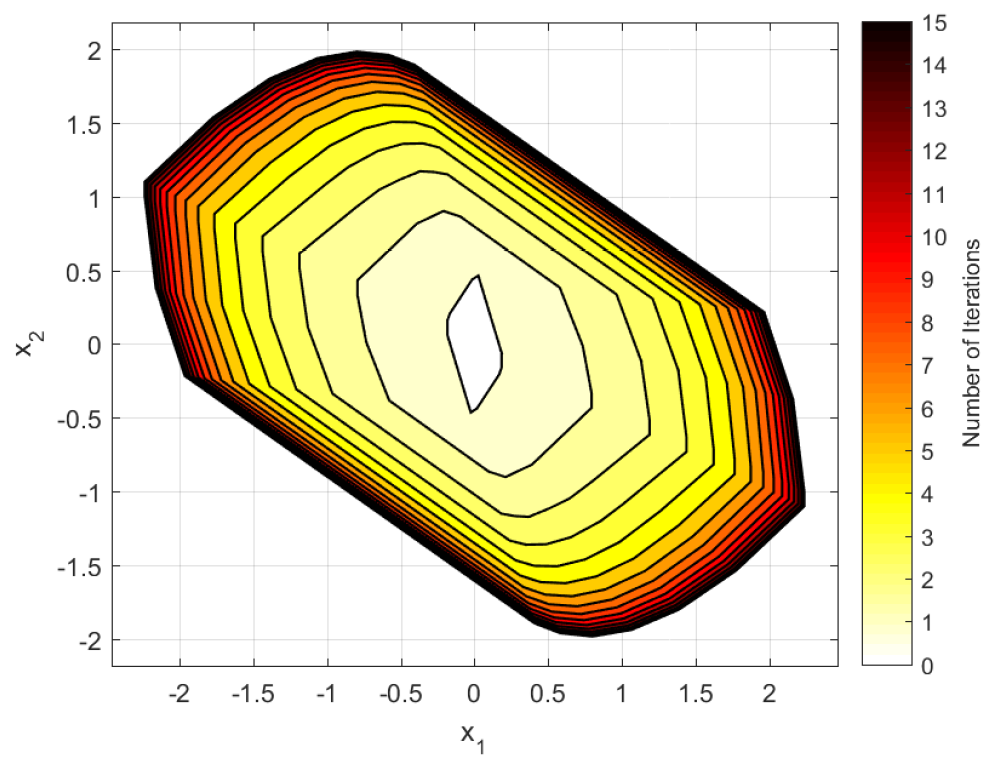 |
Abstract: This paper proposes a tube-based method for the asynchronous observation problem of discrete-time switched linear systems in the presence of amplitude-bounded disturbances. Sufficient stability conditions of the nominal observer error system under mode-dependent persistent dwell-time (MPDT) switching are first established. Taking the disturbances into account, a novel asynchronous MPDT robust positive invariant (RPI) set and an asynchronous MPDT generalized RPI (GRPI) set are determined for the difference system between the nominal and disturbed observer error systems. Further, the global uniform asymptotical stability of the observer error system is established in the sense of converging to the asynchronous MPDT GRPI set, i.e., the cross section of the tube of the observer error system. Finally, the proposed results are validated on a space robot manipulator example. |